Jacob Chalk*1, Jaesung Huh*2, Evangelos Kazakos3, Andrew Zisserman2 and Dima Damen1
1University of Bristol, Dept. of Computer Science, 2University of Oxford, VGG, 3Czech Technical University in Prague
*: Indicates equal contribution
Abstract
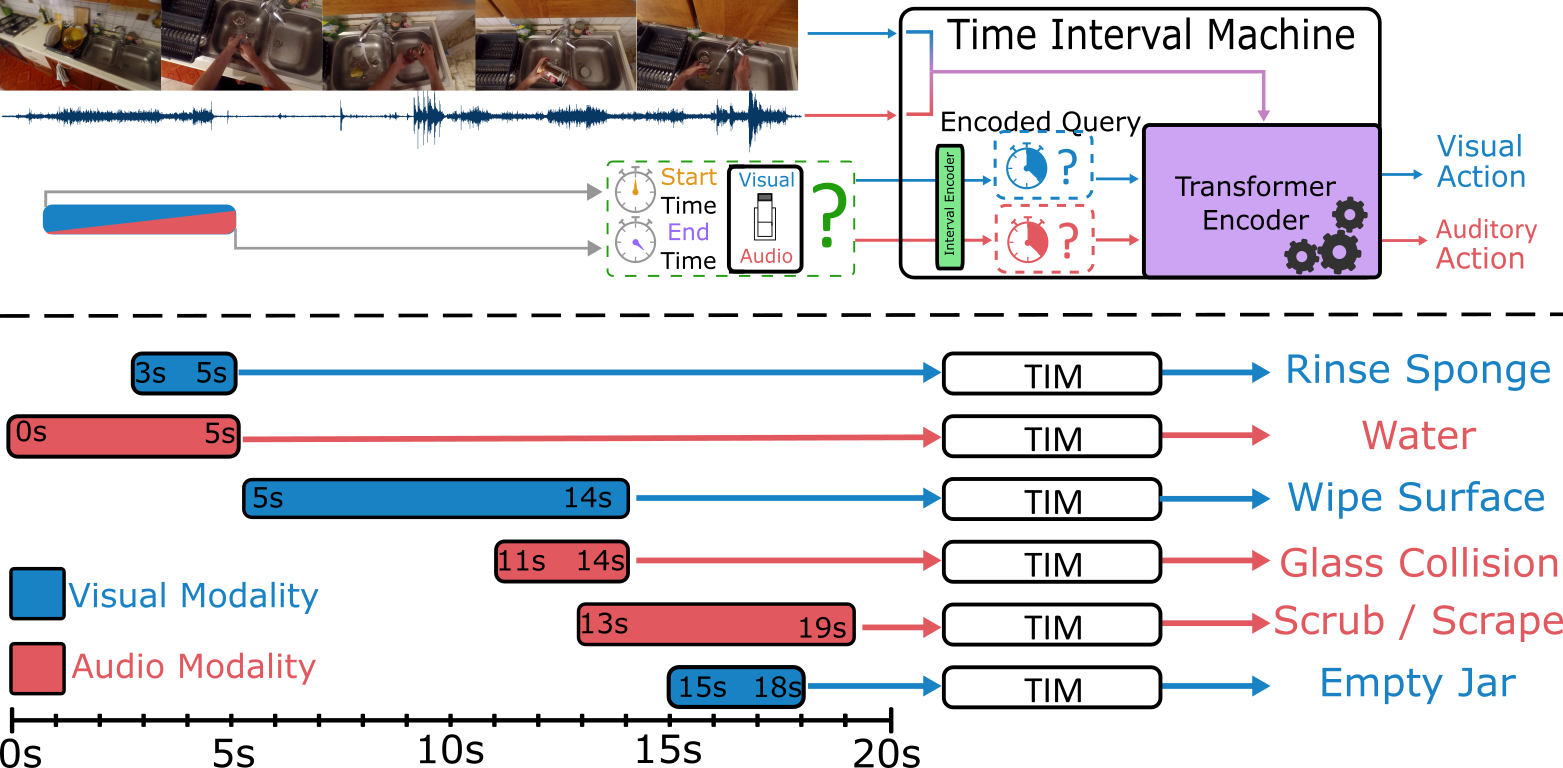
Diverse actions give rise to rich audio-visual signals in long videos. Recent works showcase that the two modalities of audio and video exhibit different temporal extents of events and distinct labels. We address the interplay between the two modalities in long videos by explicitly modelling the temporal extents of audio and visual events. We propose the Time Interval Machine (TIM) where a modality-specific time interval poses as a query to a transformer encoder that ingests a long video input. The encoder then attends to the specified interval, as well as the surrounding context in both modalities, in order to recognise the ongoing action.
We test TIM on three long audio-visual video datasets: EPIC-KITCHENS, Perception Test, and AVE, reporting state-of-the-art (SOTA) for recognition. On EPIC-KITCHENS, we beat previous SOTA that utilises LLMs and significantly larger pre-training by 2.9% top-1 action recognition accuracy. Additionally, we show that TIM can be adapted for action detection, using dense multi-scale interval queries, outperforming SOTA on EPIC-KITCHENS-100 for most metrics, and showing strong performance on the Perception Test. Our ablations show the critical role of integrating the two modalities and modelling their time intervals in achieving this performance. Code and models at: https://github.com/JacobChalk/TIM.
Video
Downloads
Bibtex
@InProceedings{Chalk_2024_CVPR,
author = {Chalk, Jacob and Huh, Jaesung and Kazakos, Evangelos and Zisserman, Andrew and Damen, Dima},
title = {{TIM}: {A} {T}ime {I}nterval {M}achine for {A}udio-{V}isual {A}ction {R}ecognition},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2024},
pages = {18153-18163}
}
Acknowledgements
This work uses public datasets. It is supported by EPSRC Doctoral Training Program, EPSRC UMPIRE EP/T004991/1 and EPSRC Programme Grant VisualAI EP/T028572/1; and by the use of the EPSRC funded Tier 2 facility JADE-II.